XLS Considered Harmful
Google's ASIC teams look impressive from the outside thanks to their mobile SoCs and TPUs. Separately, Google has an internal HLS tool called XLS, which is also open-sourced. This post gives a brief overview of what XLS is, the upsides, and its downsides.
What is XLS?
XLS is Google’s in-house open-source HLS tool. The developers call it "mid-level synthesis", but it is more accurately described as a transactional-level HLS. The language consists of three main components: functions, processes, and channels.
Functions describe combinational logic, channels represent module ports (usually latency-insensitive), and processes are a composition of functions, channels, and sequential logic. Given a circuit description, the compiler can automatically pipeline it based on an internal delay model, aiming to help timing closure. I'll discuss this in detail later.
What XLS Gets Right
Even if you don't buy into the overall approach, there are a few design decisions worth calling out.
IR
The IR design is clean. First, XLS uses a sea-of-nodes representation, which models the IR as a graph. As circuits are inherently graphs, writing optimization passes becomes much simpler than in SSA-style hardware IRs.
Take Dead Code Elimination (DCE) pass as an example. In XLS, DCE can be implemented as a straightforward traversal in a graph IR. In FIRRTL, the DCE pass spans over 500 lines of Scala. The complexity comes from the SSA-style representation, which requires two traversals: one to build an internal graph representation, and another to traverse it.
- XLS DCE pass
int64_t removed_count = 0;
absl::flat_hash_set<Node*> unique_operands;
while (!worklist.empty()) {
Node* node = worklist.front();
worklist.pop_front();
// A node may appear more than once as an operand of 'node'. Keep track of
// which operands have been handled in a set.
unique_operands.clear();
for (Node* operand : node->operands()) {
if (unique_operands.insert(operand).second) {
if (HasSingleUse(operand) && is_deletable(operand)) {
worklist.push_back(operand);
}
}
}
VLOG(3) << "DCE removing " << node->ToString();
XLS_RETURN_IF_ERROR(f->RemoveNode(node));
removed_count++;
}
- Scala FIRRTL DCE pass
class DeadCodeElimination extends Transform with RegisteredTransform with DependencyAPIMigration {
private type LogicNode = MemoizedHash[WrappedExpression]
private object LogicNode {
def apply(moduleName: String, expr: Expression): LogicNode =
WrappedExpression(Utils.mergeRef(WRef(moduleName), expr))
def apply(moduleName: String, name: String): LogicNode = apply(moduleName, WRef(name))
def apply(component: ComponentName): LogicNode = {
// Currently only leaf nodes are supported TODO implement
val loweredName = LowerTypes.loweredName(component.name.split('.'))
apply(component.module.name, WRef(loweredName))
}
def apply(ext: ExtModule): LogicNode = LogicNode(ext.name, ext.name)
}
... Many lines of code
private def createDependencyGraph(
instMaps: collection.Map[String, collection.Map[String, String]],
doTouchExtMods: Set[String],
c: Circuit
): MutableDiGraph[LogicNode] = {
val depGraph = new MutableDiGraph[LogicNode]
c.modules.foreach {
case mod: Module => setupDepGraph(depGraph, instMaps(mod.name))(mod)
case ext: ExtModule =>
val node = LogicNode(ext)
if (!doTouchExtMods.contains(ext.name)) depGraph.addPairWithEdge(circuitSink, node)
ext.ports.foreach {
case Port(_, pname, _, AnalogType(_)) =>
depGraph.addPairWithEdge(LogicNode(ext.name, pname), node)
depGraph.addPairWithEdge(node, LogicNode(ext.name, pname))
case Port(_, pname, Output, _) =>
val portNode = LogicNode(ext.name, pname)
depGraph.addPairWithEdge(portNode, node)
// Also mark all outputs as circuit sinks (unless marked doTouch obviously)
if (!doTouchExtMods.contains(ext.name)) depGraph.addPairWithEdge(circuitSink, portNode)
case Port(_, pname, Input, _) => depGraph.addPairWithEdge(node, LogicNode(ext.name, pname))
}
}
// Connect circuitSink to ALL top-level ports (we don't want to change the top-level interface)
val topModule = c.modules.find(_.name == c.main).get
val topOutputs = topModule.ports.foreach { port =>
depGraph.addPairWithEdge(circuitSink, LogicNode(c.main, port.name))
}
depGraph
}
private def deleteDeadCode(
instMap: collection.Map[String, String],
deadNodes: collection.Set[LogicNode],
moduleMap: collection.Map[String, DefModule],
renames: MutableRenameMap,
topName: String,
doTouchExtMods: Set[String]
)(mod: DefModule
): Option[DefModule] = {
... Many more lines of code
}
def run(state: CircuitState, dontTouches: Seq[LogicNode], doTouchExtMods: Set[String]): CircuitState = {
... Even more lines of code
}
def execute(state: CircuitState): CircuitState = {
val dontTouches: Seq[LogicNode] = state.annotations.flatMap {
case anno: HasDontTouches =>
anno.dontTouches
// We treat all ReferenceTargets as if they were local because of limitations of
// EliminateTargetPaths
.map(rt => LogicNode(rt.encapsulatingModule, rt.ref))
case o => Nil
}
val doTouchExtMods: Seq[String] = state.annotations.collect {
case OptimizableExtModuleAnnotation(ModuleName(name, _)) => name
}
val noDCE = state.annotations.contains(NoDCEAnnotation)
if (noDCE) {
logger.info("Skipping DCE")
state
} else {
run(state, dontTouches, doTouchExtMods.toSet)
}
}
}
Another good decision they made was to avoid compiler dialects. Compared to CIRCT which has many dialects and can make pass interoperability harder, XLS avoids that layer of complexity.
Generic Tooling Side
XLS also offers some strong features in terms of generic tooling.
- Inline testbench support is an improvement over writing Verilog testbenches
- In XLS, the design can be JIT'ed into native code to perform functional simulation, a benefit of the custom compiler approach. The simulator runs fast and allows printf debugging
- Although more of a compliment towards Bazel, tight integration with it enables caching and incremental compilation, providing a tight edit-run-debug loop
Where XLS Fits Poorly
Lack of Control Flow Synthesis
The biggest issue, in my view, is that the abstraction boundary is a mismatch for many of the designs people use HLS for. Traditional HLS1 has a clear advantage over RTL because it supports control-flow synthesis. Automating this process removes a major burden, since debugging control flow is where hardware designers spend a large portion of their time.
XLS, however, does not support control-flow synthesis, which is the key selling point of HLS. Without it, implementing anything with a nontrivial FSM requires manually instantiating all the hardware state and control logic, rather than expressing the design in an imperative style. At that point, writing XLS is not much different from writing RTL.
The code block below is a GCD module expressed in XLS. As one can see, all the necessary state to express the FSM (i.e., GCDState) has been explicitly instantiated by the programmer. The next function closely resembles an FSM written in RTL.
struct GCDState<N: u32> {
fsm: u1,
gcd: uN[N],
tmp: uN[N],
}
proc GCD<N: u32> {
type UInt = uN[N];
io_x: chan<UInt> in;
io_y: chan<UInt> in;
io_gcd: chan<UInt> out;
init {
GCDState {
fsm: u1:0,
gcd: UInt:0,
tmp: UInt:0,
}
}
config(
x: chan<UInt> in,
y: chan<UInt> in,
gcd: chan<UInt> out
) {
(x, y, gcd)
}
next(tok: token, state: GCDState) {
if (state.fsm == u1:0) {
let (tok_x, x) = recv(tok, io_x);
let (tok_y, y) = recv(tok, io_y);
let tok = join(tok_x, tok_y);
GCDState{ fsm: u1:1, gcd: x, tmp: y }
} else {
let gcd = if (state.gcd > state.tmp) { state.gcd - state.tmp }
else { state.tmp };
let tmp = if (state.gcd > state.tmp) { state.tmp }
else { state.tmp - state.gcd };
let fsm = if (tmp == UInt:0) { u1:0 }
else { u1:1 };
let tok = if (fsm == u1:0) { send(tok, io_gcd, gcd) }
else { tok };
GCDState{ fsm: fsm, gcd: gcd, tmp: tmp }
}
}
}
One abstraction that XLS does provide is communication channels, which are essentially latency-insensitive ports. By abstracting these constructs, XLS helps avoid backpressure bugs by design 2. However, logic synthesis for latency-insensitive interfaces is far less valuable than having control flow synthesis. For example, if bus responses arrive out of order, the designer is still responsible for manually writing the control logic to handle them correctly.
Moreover, there are cases where designers need ports that are not latency-insensitive and require combinational feedback paths (e.g., priority encoders). Expressing this kind of logic using XLS channels is difficult. Designers are then forced to write suboptimal blocks that waste cycles performing ready–valid handshakes when simple combinational logic would have been sufficient.
One benefit of the channel abstraction is its use in testbenches. The XLS abstraction allows the programmer to interact with each port without explicitly performing ready–valid handshakes, which is a slight improvement over the RTL abstraction. For example, in the Tester example below, the programmer can interact with the DUT using only send and recv functions.
#[test_proc]
proc Tester {
terminator: chan<bool> out;
io_x: chan<u32> out;
io_y: chan<u32> out;
io_gcd: chan<u32> in;
init {
}
config(terminator: chan<bool> out) {
let (x_p, x_c) = chan<u32>("x");
let (y_p, y_c) = chan<u32>("y");
let (gcd_p, gcd_c) = chan<u32>("gcd");
spawn GCD<u32:32>(x_c, y_c, gcd_p);
(terminator, x_p, y_p, gcd_c)
}
next(tok: token, state: ()) {
let tok_x = send(tok, io_x, u32:8);
let tok_y = send(tok, io_y, u32:12);
let tok = join(tok_x, tok_y);
let (tok, gcd) = recv(tok, io_gcd);
assert_eq(gcd, u32:4);
send(tok, terminator, true);
}
}
In summary, in XLS, the compiler is doing all the "easy work" of taking care of latency insensitive interfaces while deferring all the "hard work" of control-flow design to the engineer.
One Should Trust Synthesis
The major selling point of XLS is its automatic pipelining capabilities. It uses a delay estimation model for a particular technology (currently ASAP7) to automatically insert pipeline stages and cut critical paths. However, pushing pipelining decisions into the frontend can be hard to justify when the downstream flow already performs retiming/physical optimization based on real timing constraints, especially when the frontend delay model diverges from post-synthesis/post-P&R reality.
For latency-insensitive interfaces, queues between ports already introduce extra stages that break up long combinational paths. For combinational logic, traditional synthesis tools generally perform superior retiming. And since XLS ultimately emits Verilog, the downstream synthesis tool will run retiming on the block anyway.
One may wonder how a compiler can arbitrarily insert pipeline stages without breaking functional correctness. This circles back to XLS’s abstraction: module boundaries are latency-insensitive. To support frontend retiming, XLS must restrict the abstractions available to designers, which ultimately harms both productivity and QoR.
One may argue that XLS can reduce iteration time when fixing critical paths. While it's true that quick iteration is possible using the delay model (since it avoids running synthesis) this falls apart as soon as the model is inaccurate. In practice, the delay model will never match the accuracy of real synthesis tools, especially now that modern CAD flows perform physical synthesis.
The GitHub issue below illustrates how XLS's frontend QoR (Quality of Results) prediction can lead to problems. Because XLS tries to pipeline the design in the HDL frontend, small changes in how the code is written can affect the estimated QoR. In reality, however, the downstream synthesis tool will resolve these issues regardless of how the frontend is structured.
Custom Compiler Should be Avoided
Now, let's discuss some of their software engineering decisions. The XLS team took the bold step of building a custom compiler from scratch, which is a double-edged sword. On one hand, it provides the freedom to design according to specific needs, potentially leading to better ergonomics and enabling native language-level simulations. On the other hand, it involves a significant amount of work to get everything set up and functioning properly.
In my experience with XLS3, the disadvantages seemed to outweigh the benefits. Here is a list of limitations I encountered from a purely software engineering perspective:
- Modules in XLS are parameterized using type parameters, rather than standard function arguments (e.g.,
proc GCD<N: u32>in the GCD example above). This is unergonomic - The compiler does not support automatic bit-width inference, so the programmer must specify the type of each wire explicitly. This requirement makes the code verbose and cumbersome. While some might argue that width inference isn't crucial, those who have used an HDL with width inference (e.g., Chisel) will understand how much easier it is to write code without having to manage these intricate details of the design.
- They implemented a standard library to handle basic tasks like reading files, which is necessary for writing testbenches. In contrast, if they had used an embedded DSL, handling files containing testbench data would have been much simpler. While this may not impact the end user significantly, it likely required a considerable amount of effort from the engineers
- Miscellaneous compilation bugs. I encountered issues compiling a
forstatement while trying to create a multi-banked SRAM in my design. It appears that others have faced similar difficulties. For example, in the XLS ZStd implementation, the programmer had to hand-unroll the SRAM banks because theforstatement was broken (this example also highlights how verbose the code becomes due to the lack of type inference)
The XLS team would have had an easier time with an embedded DSL approach, as it would provide many benefits: generic type inference, fewer compiler bugs, build tools, and access to existing software libraries.
Fun facts
One interesting aspect of this project is that there was a Hacker News article about this four years ago. Many comments on that article mention the same problems I've highlighted, such as the lack of control flow synthesis and poor abstraction boundaries.
"For those that aren't familiar, control flow - or non "Directed Acyclical graphs" are the hard part of HLS. This looks like a fairly nice syntax compared to the bastardisations of C that Intel and Xilinx pursue for HLS but I'm not sure this is bringing anything new to the table."
"They describe it as HLS, and it definitely looks like HLS to me. But maybe we have different definitions. Either way, it seems to be targeting a strange subset of problems: it doesn't look high level enough to be easy to use for non-hardware designers (I don't think this goal is achievable, but it is at least a worthy goal), and it doesn't seem low-level enough to allow predictable performance."
"Take this language for example - it cannot express any control flow. It's feed forward only. Which essentially means, it is impossible to express most of the difficult parts of the problems people solve in hardware. I hate Verilog, I would love a better solution, but this language is like designing a software programming language that has no concept of run-time conditionals."
Conclusion
Overall, XLS is unsuitable for initial prototyping of designs, let alone for tapeouts. The abstraction level isn't high enough to provide a productivity advantage over RTL, and the generated RTL will have lower QoR compared to hand-written RTL implementations. The automatic pipelining feature is not especially compelling if your downstream synthesis flow already performs retiming, and when the accuracy of their delay model is questionable. The ergonomics of the frontend language do not enhance productivity. Integration testing in a full SoC context is also challenging because you need to write glue code to integrate the generated Verilog into the SoC, although this issue is common among many HLS tools.
Addendum
2025/11/13
A developer closely associated with XLS started writing publicly about applying XLS-like tooling outside Google. One example is the xlsynth organization. There is also a blog post describing code-generation options and pipelining/retiming examples:
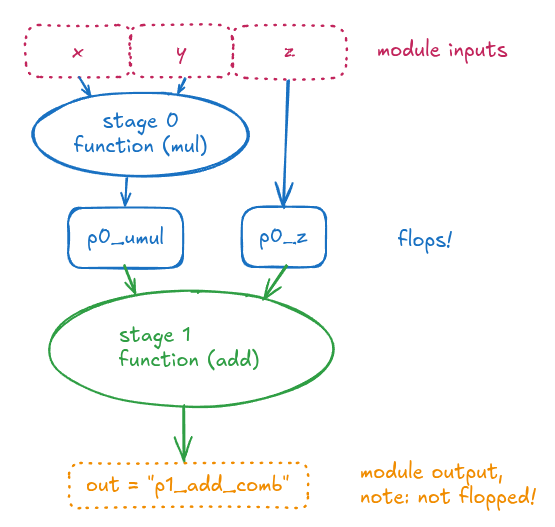
The post uses XLS to insert two pipeline stages to x * y + z.
It is notable, however, that the multiply operation (blue circle) is creating a “combinational overhang” on input, i.e. there is a combinational logic cloud (via the multiply operation) that the inputs x and y pass through immediately after entering this module. These are also typically seen as “input to register” (or “register to output”, for the green circle) delays in a timing report.
The implication of this is that the instantiating module has to be aware of how much of a clock cycle that “combinational overhang” is going to require, because the instantiator needs to make sure there is that much slack available in the clock cycle for the inputs it feeds as x and y , in order to close timing.
One point that comes up in these discussions is "combinational overhang", which simply means input-to-register (or register-to-output) delay as seen from a module boundary.
Using I/O flops to increase abstraction
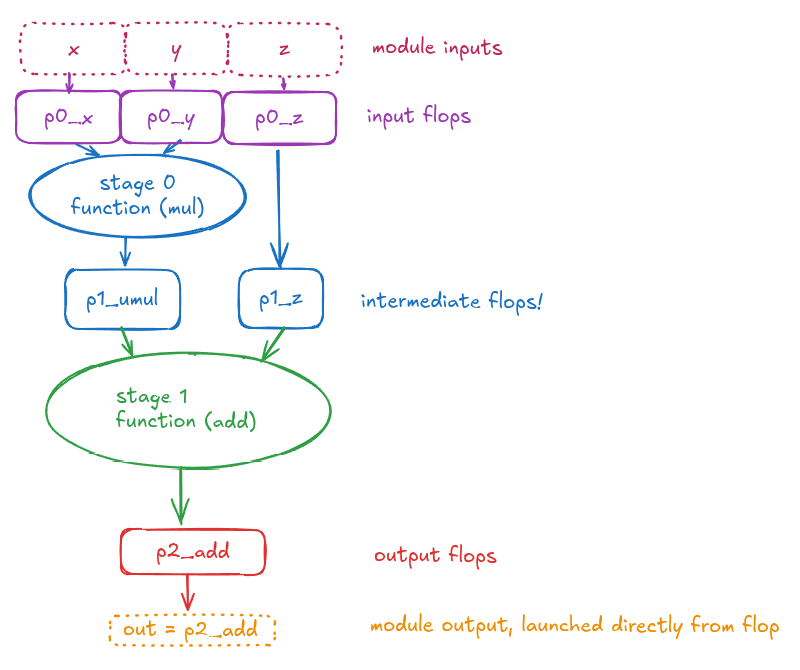
One common way to prevent timing abstraction leakage across boundaries is to use I/O flops ("flop sandwich"), which can make the block's timing contract cleaner.
In many flows, a common convention is to add registers at the end of the combinational logic and rely on downstream synthesis/retiming to handle the remaining timing details. Fancy circuit delay modeling or automatic pipelining is not required.
Citations
- XLS github issue - premature optimization is the real issue
- XLS ZStd implementation
- Hacker News article
Catapult or SystemC.
Technically, backpressure bugs can still happen.
Or perhaps in my unsuccessful attempt to use it